 ACL 2023
ACL 2023
TencentPretrain: A Scalable and Flexible Toolkit for Pre-training Models of Different Modalities
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL 2023)
我本科毕业于中南大学,博士毕业于深圳大学。主要研究方向为大模型预训练,包括预训练方法、数据工程与合成数据,是 UER-py、TencentPretrain、Linly、CLUE Benchmark、CSL 等开源项目的核心作者。当前我聚焦于知识语境(Knowledge Context)研究,探索如何将数据的语境信息引入预训练过程,提升LLM预训练的数据效能。
我正在为知识语境系列研究寻找合作伙伴,欢迎联系。
News: 我们最近发布了一篇综述文章 《LLM预训练数据工程的最佳实践》。
完整列表见 Google Scholar。
ACL 2023
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL 2023)
 COLING 2022
COLING 2022
Proceedings of the 29th International Conference on Computational Linguistics (COLING 2022)
 COLING 2020
COLING 2020
Proceedings of the 28th International Conference on Computational Linguistics (COLING 2020)
 Oral
ACM MM 2024
Oral
ACM MM 2024
Proceedings of the 32nd ACM International Conference on Multimedia (ACM MM 2024)
2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2024)
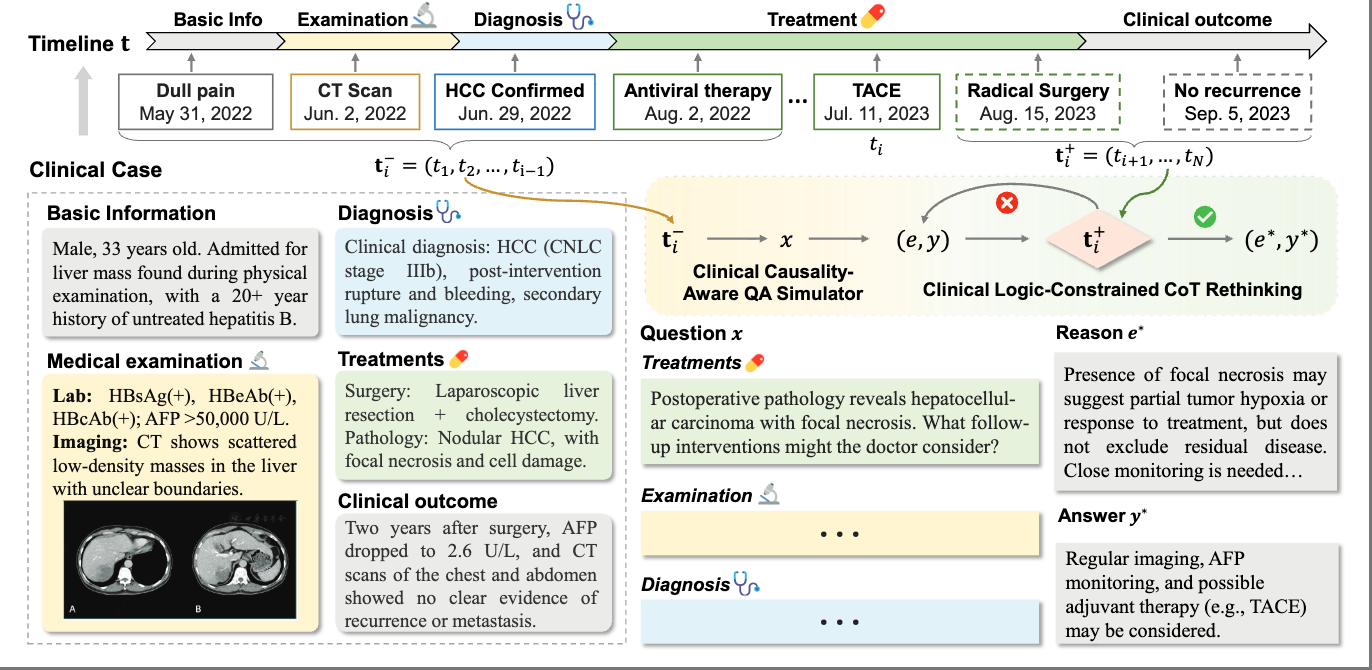 Oral
AAAI 2026
Oral
AAAI 2026
Proceedings of the AAAI Conference on Artificial Intelligence (AAAI 2026)
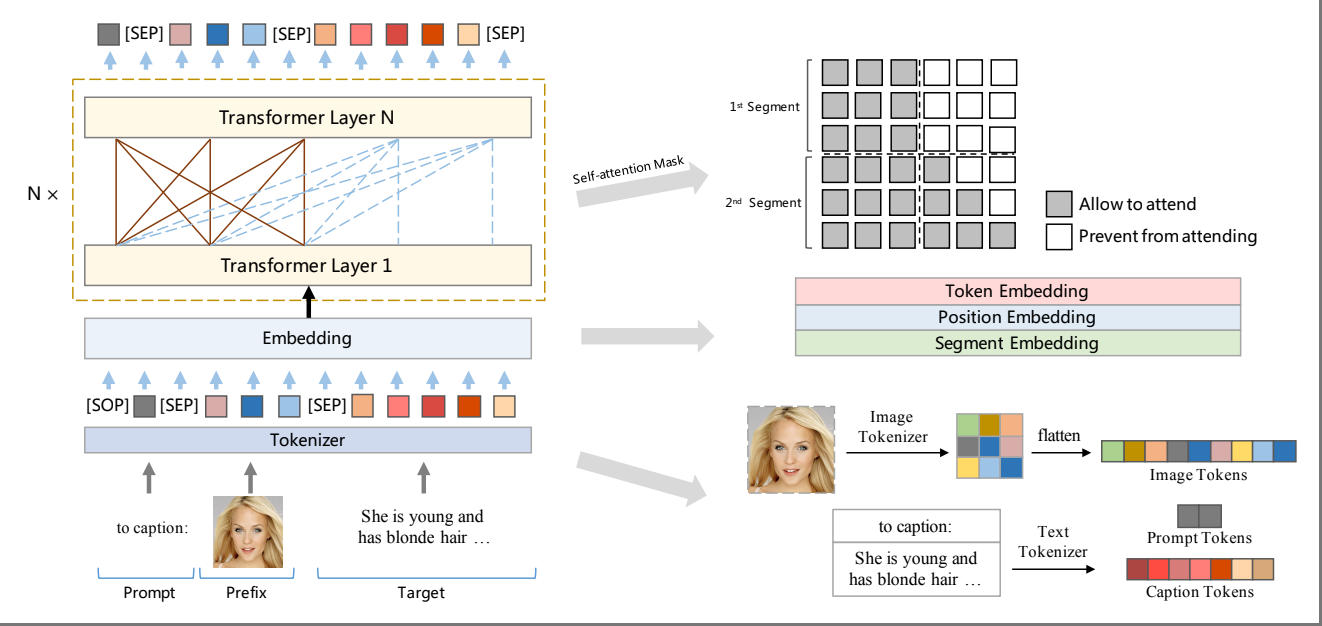 ACM MM 2022
ACM MM 2022
Proceedings of the 30th ACM International Conference on Multimedia (ACM MM 2022)
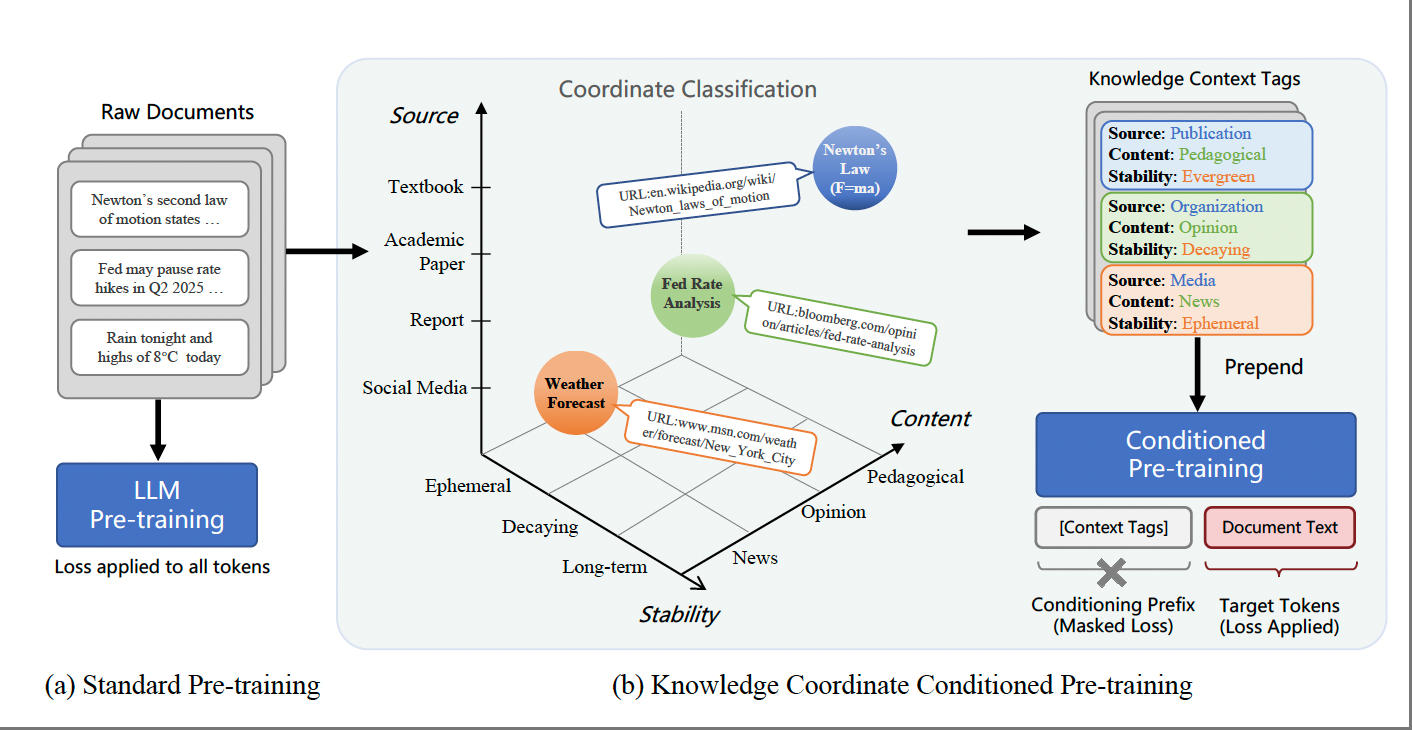 ACL 2026
ACL 2026
The 64th Annual Meeting of the Association for Computational Linguistics (ACL 2026)
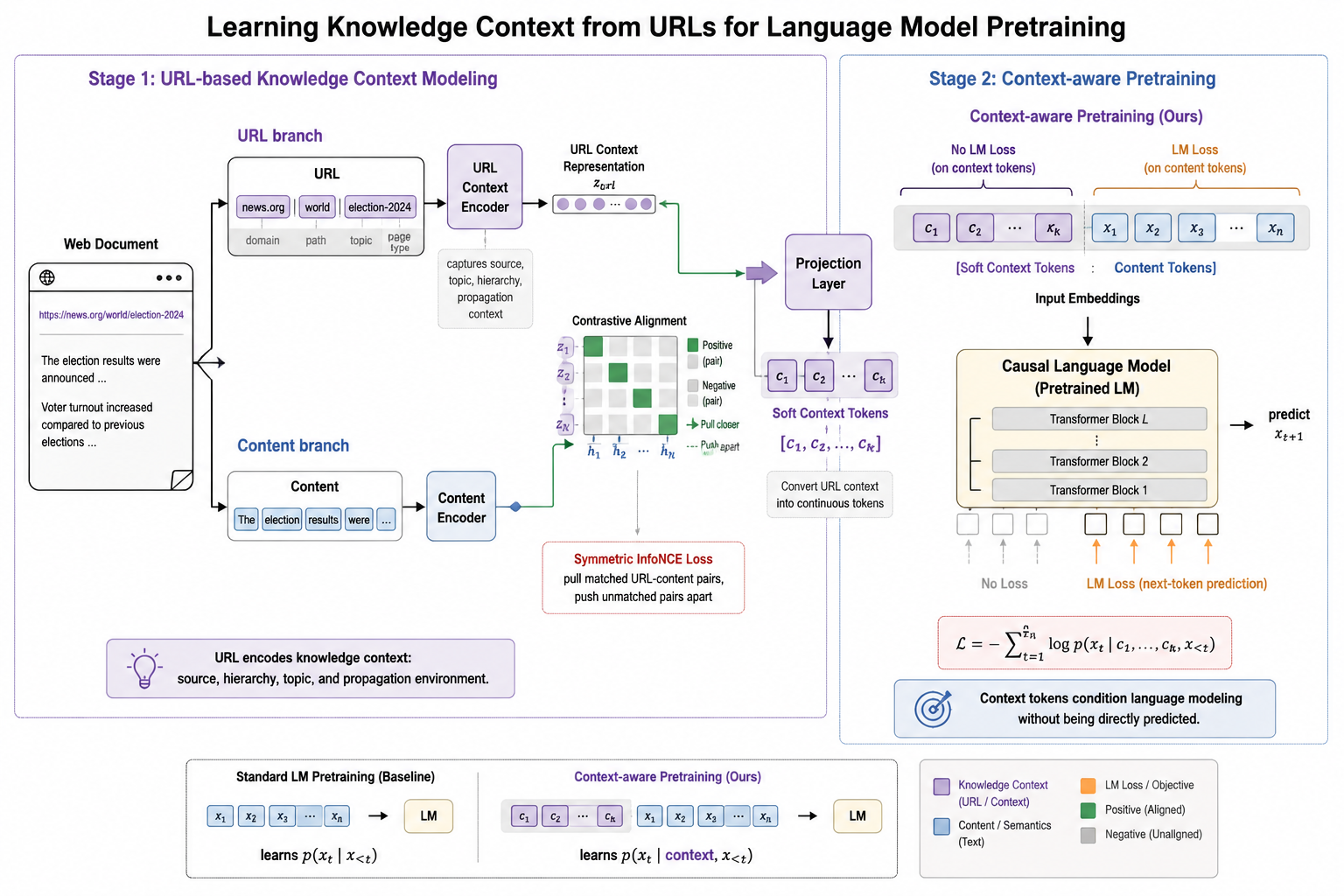
在现实世界中,人类获取信息时天然依赖语境,而文本信息也由语义和语境两个维度构成。语义对应文本的具体内容,语境则描述这段内容产生的背景条件,包括由谁发布、通过什么载体传播、在多长时间内有效。同一条知识在不同语境下,其可信度、适用范围和时效性可能完全不同。当前预训练主要让模型学习纯文本序列,这与人类在语境中理解知识的方式存在显著差异。
当前预训练将语料处理为纯文本序列,模型仅获取信息在语义的投影。信息来源、载体、时间等元信息在预处理阶段被抛弃,使模型难以像人类一样在语境中理解知识。我们希望建立有效的语境表征方法,从而构建语境-语义联合表示,使模型在预训练阶段即可显式感知每条知识的语境属性,从而界定知识的适用边界与可信层级。
围绕上述目标,我们从模型和数据两个方向展开了一系列研究。

数据筛选与数据合成当前是提升预训练数据效能的主流路径,但二者共享一个隐含假设,即数据质量是全局的属性。在该假设下,数据工程的任务是尽可能保留高质量样本、剔除或替换低质量样本。
知识语境挑战的正是这一假设。首先,数据质量本身是一个主观概念,目前缺乏公认的客观评估标准,不同筛选策略对同一样本的判断可能大相径庭。数据筛选在训练前替模型做出取舍,知识语境则将判断交还给模型:通过显式的语境信号,使模型在不同语境下自动赋予信息不同的权重与时效。由此产生两点实质差异。其一,大量被筛选策略丢弃的数据在正确语境下重新具有学习价值,数据利用率提升。其二,模型获得对知识成立条件的感知,而非仅记忆知识内容。从这个意义上,知识语境与数据工程并非替代关系,而是工作在不同层次:数据工程决定训练什么,知识语境决定如何训练。
从信息传播的视角看,真实世界中的信息始终在语义与语境两个维度上共同存在:一段文本不仅承载内容本身,也携带其来源、载体、时效与受众等背景条件。当前预训练仅使用了信息在语义维度上的投影,语境维度在数据预处理阶段被舍弃,模型所见的实际上是真实信息的降维表示。知识语境的目标是恢复这一被丢弃的维度,构建更完整、更稳固的世界信息表示,从而提升数据效能。
这一定位决定了知识语境在大规模预训练中的可扩展性。语境维度与语义内容在信息上正交,因此语境带来的增益与架构改进、数据规模增长等已有方向的增益应当是加性的,而非抢占同一份改进空间。此外,语境信息在原始数据中天然存在,包括 URL、时间戳、发布源等,而在当前的数据清洗流程中被当作噪声丢弃。这意味着该方向的数据天花板与互联网本身同步增长,无需依赖人工标注或合成数据。
大模型确实能从共现统计中隐式区分部分语境,如学术论文与网络评论的语体差异。但隐式学习存在难以通过 scaling 解决的问题。首先是不可分离,语境信息与语义信息共享同一套参数与注意力容量,二者在学习过程中相互竞争。其次是无法显式处理冲突,当语料中存在相互矛盾的陈述时,隐式学习只能以统计方式折中,难以表达对不同来源可信度的区分。
显式建模的意义不在于扩展模型本来做不到的能力,而在于将混杂于参数中的隐式信号剥离、使其可控。这与人类的信息处理方式一致:人在接收信息时并非仅接收文本内容,而是同时显式感知信息的来源、载体与场景,并据此调整对信息的信任度与解读方式。